


인공지능(AI)의 개념도 알았겠다, 본격적으로 AI 모델링을 배워보기로 했다. 텐서플로, 파이토치처럼 언젠가 기사에 썼던 ‘머신러닝 라이브러리’를 공부하게 될 줄 알았다. 하지만 먼저 마주한 것은 1만 개 이상의 열(칼럼)로 이뤄진 CSV 확장자 데이터(tabular) 파일이었다.
 “머신러닝 실행을 위한 코드는 4줄, 딥러닝은 8줄이면 충분합니다. 가장 중요한 것은 데이터입니다.” AI는 데이터를 갖고 패턴을 만들어 자동화하고 예측하는 도구인 만큼 데이터가 없다면 AI도 성립할 수 없다. 얼마나 잘 정돈된 데이터를 입력하는가에 따라 결과물도 천차만별로 나올 수밖에 없다. 한마디로 ‘가비지 인, 가비지 아웃(garbage in, garbage out·쓰레기를 넣으면 쓰레기가 나온다)’이다. AI 모델링은 데이터를 확보하고 AI가 학습할 수 있도록 데이터를 정리하는 전처리 과정이 70%를 차지한다.
“머신러닝 실행을 위한 코드는 4줄, 딥러닝은 8줄이면 충분합니다. 가장 중요한 것은 데이터입니다.” AI는 데이터를 갖고 패턴을 만들어 자동화하고 예측하는 도구인 만큼 데이터가 없다면 AI도 성립할 수 없다. 얼마나 잘 정돈된 데이터를 입력하는가에 따라 결과물도 천차만별로 나올 수밖에 없다. 한마디로 ‘가비지 인, 가비지 아웃(garbage in, garbage out·쓰레기를 넣으면 쓰레기가 나온다)’이다. AI 모델링은 데이터를 확보하고 AI가 학습할 수 있도록 데이터를 정리하는 전처리 과정이 70%를 차지한다.
가장 먼저 해야 할 일은 데이터의 전체적인 모습을 파악하는 것이다. 무엇에 관한 데이터인지, 이를 통해 어떤 사실을 알고 싶은지를 정리하는 게 첫 번째다. 데이터는 크게 피처(feature)와 레이블(label)로 구분된다. 피처를 x, 레이블을 y라고 부르기도 한다. 피처를 활용해 레이블을 예측하는 게 AI 모델의 최종적인 목표다. 예측에 앞서 데이터를 분석하고 유용한 피처와 필요 없는 피처를 선별하는 과정을 ‘탐색적 데이터 분석(EDA: exploratory data analysis)’이라고 부른다.
가령 공유 자전거 업체가 과거 기록을 기반으로 향후 자전거 수요량을 예측하려고 한다. 대여 날짜와 시간, 온도, 습도, 풍속 등은 피처, 대여 수량은 레이블이다. 분석하지 않아도 직관적으로 알 수 있는 사실이 있다. 눈, 비가 오면 대여량이 줄어든다거나 출·퇴근 시간에 대여량이 더 많을 것이라고 생각할 수 있다.
데이터 분석과 시각화 도구를 통해 예상이 맞는지 확인하는 과정에서 데이터의 이상 여부도 파악할 수 있다. 가령 풍속 데이터가 대부분 0이었다면 바람이 불지 않은 날이 많았다기보다는 제대로 데이터를 측정한 날이 거의 없었다고 해석하는 게 더 타당하다. 이때는 풍속을 변수에서 빼줘야 한다.
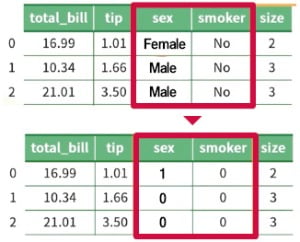
AI가 이해할 수 있는 형태로 데이터를 수정하는 것도 이 단계에서 이뤄진다. 성별 항목이 ‘남성’과 ‘여성’이라고 적혀 있다면 ‘0’과 ‘1’처럼 숫자로 바꿔주는 ‘레이블 인코딩’이 대표적이다. 비어 있는 데이터를 특정 값으로 채우거나 아예 없애기도 한다.
많은 데이터가 있어도 레이블과 관련이 없다면 예측 성능을 떨어뜨린다. 이 때문에 본인이 잘 아는 분야나 업무와 관련한 데이터로 AI에 입문하는 게 가장 좋다. (③에서 계속)
이승우 기자 leeswoo@hankyung.com
“머신러닝 실행을 위한 코드는 4줄, 딥러닝은 8줄이면 충분합니다. 가장 중요한 것은 데이터입니다.” AI는 데이터를 갖고 패턴을 만들어 자동화하고 예측하는 도구인 만큼 데이터가 없다면 AI도 성립할 수 없다. 얼마나 잘 정돈된 데이터를 입력하는가에 따라 결과물도 천차만별로 나올 수밖에 없다. 한마디로 ‘가비지 인, 가비지 아웃(garbage in, garbage out·쓰레기를 넣으면 쓰레기가 나온다)’이다. AI 모델링은 데이터를 확보하고 AI가 학습할 수 있도록 데이터를 정리하는 전처리 과정이 70%를 차지한다.가장 먼저 해야 할 일은 데이터의 전체적인 모습을 파악하는 것이다. 무엇에 관한 데이터인지, 이를 통해 어떤 사실을 알고 싶은지를 정리하는 게 첫 번째다. 데이터는 크게 피처(feature)와 레이블(label)로 구분된다. 피처를 x, 레이블을 y라고 부르기도 한다. 피처를 활용해 레이블을 예측하는 게 AI 모델의 최종적인 목표다. 예측에 앞서 데이터를 분석하고 유용한 피처와 필요 없는 피처를 선별하는 과정을 ‘탐색적 데이터 분석(EDA: exploratory data analysis)’이라고 부른다.
가령 공유 자전거 업체가 과거 기록을 기반으로 향후 자전거 수요량을 예측하려고 한다. 대여 날짜와 시간, 온도, 습도, 풍속 등은 피처, 대여 수량은 레이블이다. 분석하지 않아도 직관적으로 알 수 있는 사실이 있다. 눈, 비가 오면 대여량이 줄어든다거나 출·퇴근 시간에 대여량이 더 많을 것이라고 생각할 수 있다.
데이터 분석과 시각화 도구를 통해 예상이 맞는지 확인하는 과정에서 데이터의 이상 여부도 파악할 수 있다. 가령 풍속 데이터가 대부분 0이었다면 바람이 불지 않은 날이 많았다기보다는 제대로 데이터를 측정한 날이 거의 없었다고 해석하는 게 더 타당하다. 이때는 풍속을 변수에서 빼줘야 한다.
AI가 이해할 수 있는 형태로 데이터를 수정하는 것도 이 단계에서 이뤄진다. 성별 항목이 ‘남성’과 ‘여성’이라고 적혀 있다면 ‘0’과 ‘1’처럼 숫자로 바꿔주는 ‘레이블 인코딩’이 대표적이다. 비어 있는 데이터를 특정 값으로 채우거나 아예 없애기도 한다.
많은 데이터가 있어도 레이블과 관련이 없다면 예측 성능을 떨어뜨린다. 이 때문에 본인이 잘 아는 분야나 업무와 관련한 데이터로 AI에 입문하는 게 가장 좋다. (③에서 계속)
이승우 기자 leeswoo@hankyung.com
관련뉴스










