


"해치야, 여의도 한강공원 주차장이 어디있는지 궁금해."
질문을 적고 약 21초가 흐르자 서울시의 브랜드 캐릭터 '해치' 얼굴 아이콘의 인공지능(AI) 챗봇이 여의도 한강공원 인근 주차장 5곳의 주소를 알려줬다. '한강공원 주차장 정보'로 연결되는 버튼도 띄워 줘 추가적인 정보도 찾아볼 수 있었다. 다만 이용 요금이나 시간 등의 구체적인 부가 정보는 따로 알아봐야 했다.
30일 서울시는 전국 지방자치단체 중 처음으로 자연어(일반적인 사회생활 과정에서 자연스럽게 사람들이 사용하는 언어)에 기반한 공공데이터 서비스를 제공하는 '서울데이터허브' 사이트를 공식적으로 열었다고 밝혔다. 이용자는 해치 아이콘의 생성형 AI에 서울시내 공공데이터 관련 질문을 하고 답을 얻을 수 있다.
서울시 공공데이터 위주로 학습했기 때문에 어떤 질문이든 시 공공데이터 관점에서 보고 관련 정보를 출력할 수 있도록 연결해 준다. 이를테면 서울 시내 전통시장 사과 물가, 최근 한 달간 시내 동네별 미세먼지 농도 변화 추이 등을 물어보고 답변받을 수 있다.
장점은 단순한 질문을 하더라도 자연어에 포함된 시 공공데이터 연계 내용을 잡아낼 경우, 구체적인 자료값은 물론 분석 결과나 경우에 따라 관련 차트 이미지와 같은 참고 자료까지 제공하는 부분이다. 이를테면 '자치구별 도서관 개수 비교 분석해줘'라고 동일하게 적었을 때 서울시 공공데이터 생성형AI와 챗GPT의 답변에서 차이를 느낄 수 있었다.
단순한 질문을 두고 서울시 공공데이터 생성형AI는 △도서관 1개당 인구수로 환산한 자치구별 도서관 비율과 순위 △최소~최대 도서관 보유 자치구 △데이터 특징과 이를 통해 도출할 수 있는 결론 △자치구별 공공도서관 개수 및 순위 차트 이미지 등을 자동으로 표출했다.
같은 질문에 대해 챗GPT는 △서울시내 전체 공공도서관 수 △자치구별 평균 도서관 수 △도서관 수가 많은 자치구와 적은 자치구 △이를 통해 얻을 수 있는 간단한 결론 정도의 정보를 제공했다. 차트나 그래프로도 표현해달라고 추가 지시어를 입력해야만 이미지를 얻을 수 있었다.
하지만 단점도 명확하다. 우선 시 공공데이터 외적인 정보는 잘 모른다는 점이다. 특정 자치구의 과일 물가 등을 물어보면 시내 전통시장 현황, 시내 해당 자치구 대규모점포 인허가 정보 등 연관 공공데이터와 연계해줄 뿐 질문한 정보를 제공받을 수는 없었다. 한강공원 주차장이 어디 있는지를 물어봤을 때는 이용료 등 실이용객들의 사용 후기를 포함한 정보를 제공하지 못했다.
이외 다른 지자체 정보를 물어보면 "저는 서울 데이터 허브의 AI챗봇이다, 다른 지자체 데이터는 제공하지 않는 점 양해 부탁드린다"는 내용이 떴다.
또 사용자 편의를 맞추기 위한 지시어를 입력했을 때 반영 될 때가 있고 반영되지 않을 때가 있었다. '한강공원 주차장 정보'를 알고 싶다고 하며 '저렴한 순서대로' '5개까지' '친근한 반말 표현을 활용해서' 등의 지시어를 추가해 몇 번 반복해 질문해 봤다. 반말 표현을 활용한 무료 주차장 주소가 뜰 때도 있고, 존댓말 표현으로 뜰 때도 있고, 정확한 요금 기준이나 자치구 등을 입력하라고 뜰 때도 있었다.
또 서울시 공공데이터 생성형AI는 한 질문에 대한 답을 준비하는 과정에서 수초~수십 초 정도가 소요됐다. 보통 1분을 넘기지는 않았다. 하지만 수초 정도로, 유사한 질문에 평균적으로 10초 이내 답변을 내놓는 챗GPT 등 대표적인 생성형AI와 비교해 보면 시간이 3~5배 정도 더 걸리는 편이었다.
따라서 실생활 관련 질문을 하거나, 사용자 편의에 맞추기 위한 다양한 지시어를 입력할 필요가 있거나, 빠른 속도로 정보를 검색해야 하는 경우라면 챗GPT, 바드 등과 같이 여러 데이터를 활용해 답변하는 생성형AI가 사용하기 보다 적합해 보였다.
추가적으로 챗GPT에 질문 입력 시 '서울시 공공데이터 내용으로만 검색해줘'라는 문장을 포함하면, 서울시 공공데이터 생성형AI와 크게 다르지 않은 답변을 제시하는 걸 확인할 수 있었다.
뉴욕, 런던, 베를린 등 세계적으로 여러 도시들이 이미 '오픈 데이터'라는 명목으로 다양한 도시 공공데이터를 제공하고 있다. 하지만 NYC Open Data, Berlin Open Data, Toronto Open Data, Barcelona Open Data, San Francisco Open Data, Sydney Data Hub 등 도시별 공공데이터 서비스 사이트는 모두 원자료나 이미 특정 방식으로 가공이 끝난 자료 위주로 제공하는 중이다.
이를테면 각 사이트 내에서는 원하는 자료를 찾을 때까지 검색에 검색을 거듭해야 하는 방식이다. 만일 즉석에서 원자료를 가공한 일부 결과물을 확인하고 싶다면, 챗GPT 등 외부 생성형AI 도구에 접속한 뒤 '특정 도시의 공공데이터 사이트 정보 중에서 검색하고 싶다'는 지시어 등을 별도로 입력해야 한다.
게다가 이 경우 일부 자료에서 검색 내용이 왜곡되는 등의 환각 현상(hallucination)이 일어날 가능성도 있다. 사용자가 외부 생성형 AI, 공공데이터 원자료 등을 일일이 골라야 하고 필요시 사후 정보검증 작업 등도 직접 해야 할 수 있다는 의미다.
이와 관련해 시는 이번 사이트 구축 작업에서는 이러한 환각 현상을 최소화하는 기술을 적용했다고 설명했다. 서울시 관계자는 "자체 플랫폼을 구축하는 과정에서 최첨단 RAG(검색 증강 생성) 솔루션에 기반한 챗봇을 도입해 환각 현상이 최소한으로 발생할 것"이라고 했다. RAG 기법은 일종의 정보의 정확도를 높이기 위한 '사실 크로스체크' 기술이다.
또 서울데이터허브 내에서는 일부 시 관련 통계지표의 '3차원 시각화' 정보를 제공하고 있어, 참고자료로 같이 활용하기 좋았다. 자치구별 막대그래프 등이 지도 위에 입체적으로 나타나고, 해치와 친구들 캐릭터 이미지가 부연 설명을 하는 형태다.
다만 일부 시각화 그래프의 경우 디자인 측면에서는 눈길을 확 끌었지만 수치 비교를 위한 기능적 측면에서는 시각적으로 뚜렷한 차이를 확인하기가 힘들었다.
그럼에도 시에 따르면 서울시 공공데이터 생성형AI와 3차원 시각화 서비스를 포함한 '서울데이터허브' 플랫폼은 지난해 11월 시범 서비스를 시작한 후 이달 20일까지를 기준으로 누적 조회 수만 6만7300건 이상, 활성 사용자 수 1만3800명을 기록했다.
강옥현 서울시 디지털도시국장은 "약 80% 이상의 시민들은 사용자 인터페이스(UI) 등 서비스에 만족했다"며 "앞으로 '주제 분석 시각화' 서비스 기능도 추가할 예정"이라고 했다. 주제 분석 시각화는 단어나 문장 등의 패턴을 분석해 자주 언급되는 주제를 버블형 차트 등으로 간결하게 시각화하는 방식이다.
오유림 기자 our@hankyung.com
 "해치야, 여의도 한강공원 주차장이 어디있는지 궁금해."
"해치야, 여의도 한강공원 주차장이 어디있는지 궁금해."질문을 적고 약 21초가 흐르자 서울시의 브랜드 캐릭터 '해치' 얼굴 아이콘의 인공지능(AI) 챗봇이 여의도 한강공원 인근 주차장 5곳의 주소를 알려줬다. '한강공원 주차장 정보'로 연결되는 버튼도 띄워 줘 추가적인 정보도 찾아볼 수 있었다. 다만 이용 요금이나 시간 등의 구체적인 부가 정보는 따로 알아봐야 했다.
30일 서울시는 전국 지방자치단체 중 처음으로 자연어(일반적인 사회생활 과정에서 자연스럽게 사람들이 사용하는 언어)에 기반한 공공데이터 서비스를 제공하는 '서울데이터허브' 사이트를 공식적으로 열었다고 밝혔다. 이용자는 해치 아이콘의 생성형 AI에 서울시내 공공데이터 관련 질문을 하고 답을 얻을 수 있다.
'서울시 공공데이터' 위주 학습…생성형AI로선 장단점 명확
서울데이터허브에서 제공하는 해치 얼굴의 AI챗봇은 오픈AI사의 챗GPT, 구글의 제미니 등 전세계적으로 각광받는 생성형AI의 '서울시 특화형 모델'이라고 할 수 있다. 시에 따르면 지난해 11월부터 시범 운영을 거쳐 이달 공식 서비스를 시작했다.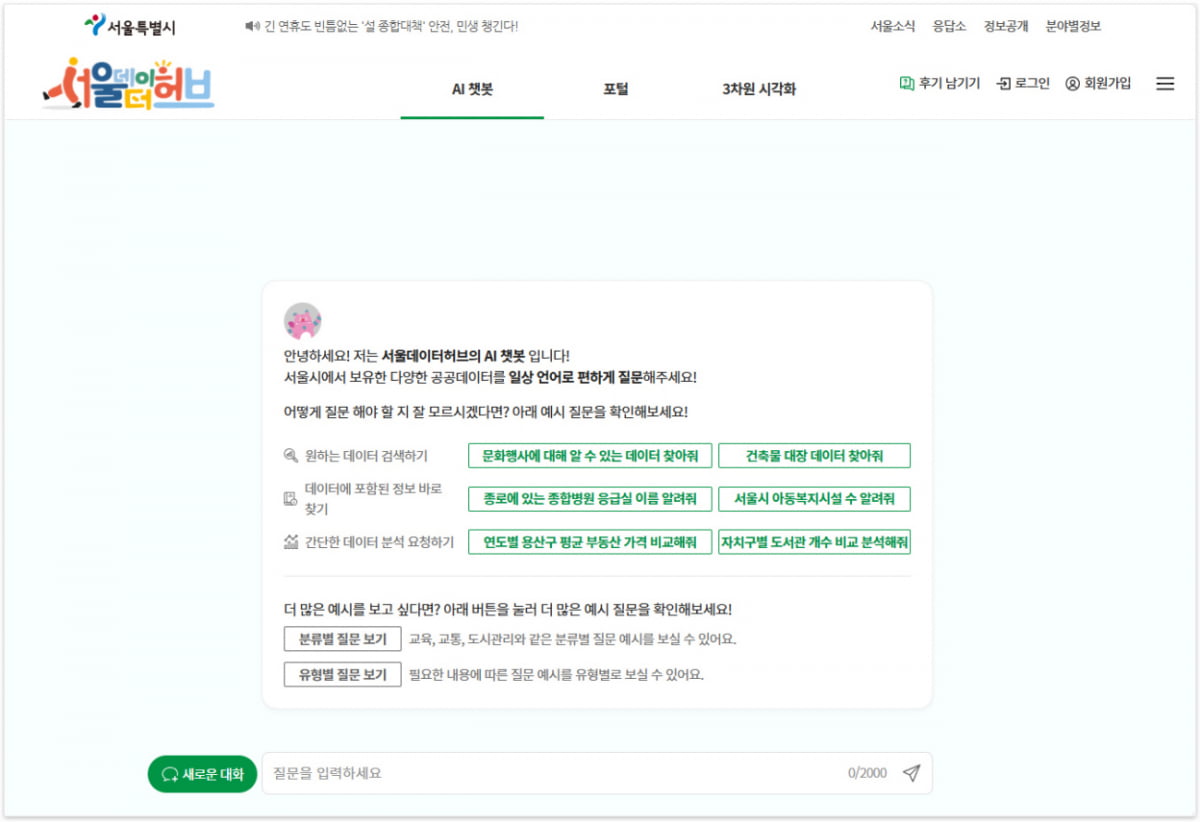
서울시 공공데이터 위주로 학습했기 때문에 어떤 질문이든 시 공공데이터 관점에서 보고 관련 정보를 출력할 수 있도록 연결해 준다. 이를테면 서울 시내 전통시장 사과 물가, 최근 한 달간 시내 동네별 미세먼지 농도 변화 추이 등을 물어보고 답변받을 수 있다.
장점은 단순한 질문을 하더라도 자연어에 포함된 시 공공데이터 연계 내용을 잡아낼 경우, 구체적인 자료값은 물론 분석 결과나 경우에 따라 관련 차트 이미지와 같은 참고 자료까지 제공하는 부분이다. 이를테면 '자치구별 도서관 개수 비교 분석해줘'라고 동일하게 적었을 때 서울시 공공데이터 생성형AI와 챗GPT의 답변에서 차이를 느낄 수 있었다.
단순한 질문을 두고 서울시 공공데이터 생성형AI는 △도서관 1개당 인구수로 환산한 자치구별 도서관 비율과 순위 △최소~최대 도서관 보유 자치구 △데이터 특징과 이를 통해 도출할 수 있는 결론 △자치구별 공공도서관 개수 및 순위 차트 이미지 등을 자동으로 표출했다.
같은 질문에 대해 챗GPT는 △서울시내 전체 공공도서관 수 △자치구별 평균 도서관 수 △도서관 수가 많은 자치구와 적은 자치구 △이를 통해 얻을 수 있는 간단한 결론 정도의 정보를 제공했다. 차트나 그래프로도 표현해달라고 추가 지시어를 입력해야만 이미지를 얻을 수 있었다.
하지만 단점도 명확하다. 우선 시 공공데이터 외적인 정보는 잘 모른다는 점이다. 특정 자치구의 과일 물가 등을 물어보면 시내 전통시장 현황, 시내 해당 자치구 대규모점포 인허가 정보 등 연관 공공데이터와 연계해줄 뿐 질문한 정보를 제공받을 수는 없었다. 한강공원 주차장이 어디 있는지를 물어봤을 때는 이용료 등 실이용객들의 사용 후기를 포함한 정보를 제공하지 못했다.
이외 다른 지자체 정보를 물어보면 "저는 서울 데이터 허브의 AI챗봇이다, 다른 지자체 데이터는 제공하지 않는 점 양해 부탁드린다"는 내용이 떴다.

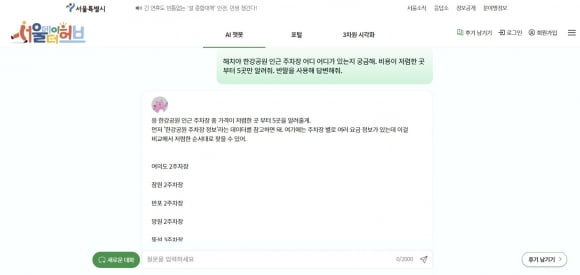
또 사용자 편의를 맞추기 위한 지시어를 입력했을 때 반영 될 때가 있고 반영되지 않을 때가 있었다. '한강공원 주차장 정보'를 알고 싶다고 하며 '저렴한 순서대로' '5개까지' '친근한 반말 표현을 활용해서' 등의 지시어를 추가해 몇 번 반복해 질문해 봤다. 반말 표현을 활용한 무료 주차장 주소가 뜰 때도 있고, 존댓말 표현으로 뜰 때도 있고, 정확한 요금 기준이나 자치구 등을 입력하라고 뜰 때도 있었다.

또 서울시 공공데이터 생성형AI는 한 질문에 대한 답을 준비하는 과정에서 수초~수십 초 정도가 소요됐다. 보통 1분을 넘기지는 않았다. 하지만 수초 정도로, 유사한 질문에 평균적으로 10초 이내 답변을 내놓는 챗GPT 등 대표적인 생성형AI와 비교해 보면 시간이 3~5배 정도 더 걸리는 편이었다.
따라서 실생활 관련 질문을 하거나, 사용자 편의에 맞추기 위한 다양한 지시어를 입력할 필요가 있거나, 빠른 속도로 정보를 검색해야 하는 경우라면 챗GPT, 바드 등과 같이 여러 데이터를 활용해 답변하는 생성형AI가 사용하기 보다 적합해 보였다.
추가적으로 챗GPT에 질문 입력 시 '서울시 공공데이터 내용으로만 검색해줘'라는 문장을 포함하면, 서울시 공공데이터 생성형AI와 크게 다르지 않은 답변을 제시하는 걸 확인할 수 있었다.
해외 주요 도시 공공데이터 사이트들과의 차별화는 '원스톱 방식'
시의 이번 시도는 '자체적인 공공데이터 원스톱 플랫폼'을 구축했다는 면에서 다른 해외 주요 도시들과 차별화된다고 볼 수 있다. 외부 생성형AI 플랫폼을 거치지 않아도, 하나의 공공데이터 플랫폼 내에서 원자료 검색은 물론 간단한 가공, 3차원 시각화 등 기타 기능을 모두 활용할 수 있기 때문이다.뉴욕, 런던, 베를린 등 세계적으로 여러 도시들이 이미 '오픈 데이터'라는 명목으로 다양한 도시 공공데이터를 제공하고 있다. 하지만 NYC Open Data, Berlin Open Data, Toronto Open Data, Barcelona Open Data, San Francisco Open Data, Sydney Data Hub 등 도시별 공공데이터 서비스 사이트는 모두 원자료나 이미 특정 방식으로 가공이 끝난 자료 위주로 제공하는 중이다.
이를테면 각 사이트 내에서는 원하는 자료를 찾을 때까지 검색에 검색을 거듭해야 하는 방식이다. 만일 즉석에서 원자료를 가공한 일부 결과물을 확인하고 싶다면, 챗GPT 등 외부 생성형AI 도구에 접속한 뒤 '특정 도시의 공공데이터 사이트 정보 중에서 검색하고 싶다'는 지시어 등을 별도로 입력해야 한다.
게다가 이 경우 일부 자료에서 검색 내용이 왜곡되는 등의 환각 현상(hallucination)이 일어날 가능성도 있다. 사용자가 외부 생성형 AI, 공공데이터 원자료 등을 일일이 골라야 하고 필요시 사후 정보검증 작업 등도 직접 해야 할 수 있다는 의미다.
이와 관련해 시는 이번 사이트 구축 작업에서는 이러한 환각 현상을 최소화하는 기술을 적용했다고 설명했다. 서울시 관계자는 "자체 플랫폼을 구축하는 과정에서 최첨단 RAG(검색 증강 생성) 솔루션에 기반한 챗봇을 도입해 환각 현상이 최소한으로 발생할 것"이라고 했다. RAG 기법은 일종의 정보의 정확도를 높이기 위한 '사실 크로스체크' 기술이다.
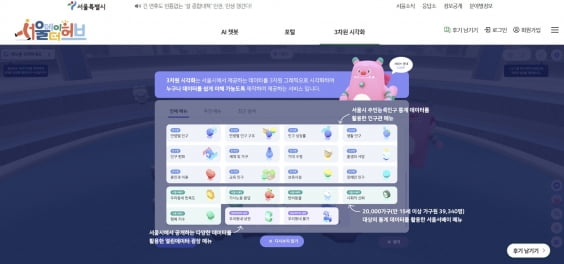
또 서울데이터허브 내에서는 일부 시 관련 통계지표의 '3차원 시각화' 정보를 제공하고 있어, 참고자료로 같이 활용하기 좋았다. 자치구별 막대그래프 등이 지도 위에 입체적으로 나타나고, 해치와 친구들 캐릭터 이미지가 부연 설명을 하는 형태다.
다만 일부 시각화 그래프의 경우 디자인 측면에서는 눈길을 확 끌었지만 수치 비교를 위한 기능적 측면에서는 시각적으로 뚜렷한 차이를 확인하기가 힘들었다.
그럼에도 시에 따르면 서울시 공공데이터 생성형AI와 3차원 시각화 서비스를 포함한 '서울데이터허브' 플랫폼은 지난해 11월 시범 서비스를 시작한 후 이달 20일까지를 기준으로 누적 조회 수만 6만7300건 이상, 활성 사용자 수 1만3800명을 기록했다.
강옥현 서울시 디지털도시국장은 "약 80% 이상의 시민들은 사용자 인터페이스(UI) 등 서비스에 만족했다"며 "앞으로 '주제 분석 시각화' 서비스 기능도 추가할 예정"이라고 했다. 주제 분석 시각화는 단어나 문장 등의 패턴을 분석해 자주 언급되는 주제를 버블형 차트 등으로 간결하게 시각화하는 방식이다.
오유림 기자 our@hankyung.com
관련뉴스












