




태국어와 말레이·인도네시아어 번역도 쉬워진다
한국전자통신연구원서 음성 데이터베이스 제작

(대전=연합뉴스) 이재림 기자 = 한국전자통신연구원(ETRI)은 국내에서 처음으로 태국어·말레이어·인도네시아어 음성 데이터베이스(DB)를 구축했다고 27일 밝혔다.
연구진은 최대한 많은 사람의 언어 자료를 얻기 위해 공개 의견수렴(크라우드 소싱·Crowd sourcing) 기법을 도입했다.
포인트 제공 방식으로 일반 사용자 참여를 유도한 결과 2만5천여 명이 발화에 나섰다.
단순히 양만 늘었을 뿐 아니라 정확도까지 확보했다.
서로 틀린 부분을 바로 잡아주는 집단 지성 덕분이다.
실제 외부 감리 업체 측정 결과 99% 이상의 높은 품질을 확인했다고 연구진은 설명했다.
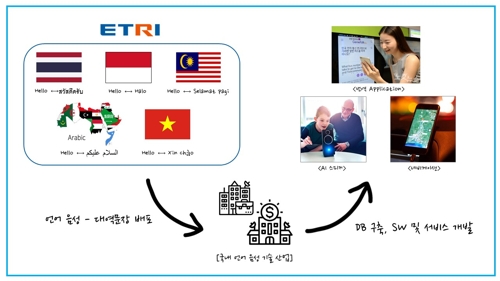
ETRI는 아울러 기존보다 데이터양을 늘린 아랍어·베트남어 DB와 영어 대역문장(300만 발화)을 함께 만들었다.
대역문장은 원문 단어나 구절을 맞대어 번역해, 두 언어가 쌍을 이루도록 만들었다.
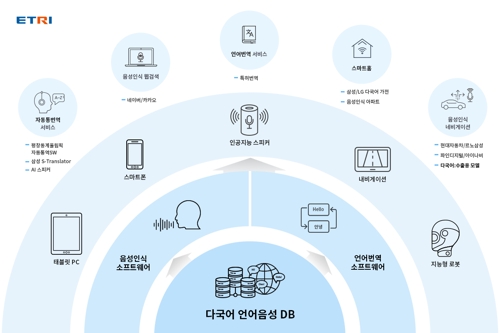
이 DB들은 인공지능(AI) 스피커·내비게이션·사물인터넷(IoT) 등 음성인식 시스템과 번역 소프트웨어 개발에 기초로 쓰일 예정이다.
예컨대 국내 포털 사이트를 비롯한 업체의 경우 DB 구축 비용을 기존보다 줄일 수 있을 것으로 ETRI는 보고 있다.
외국 업체 것을 사는 데 들어가는 비용의 5% 수준에서 DB를 제공할 방침이기 때문이다.
ETRI 음성지능연구그룹 윤 승 박사는 "이 DB를 통해 언어음성기술을 개발하면 다양한 외국 신규시장 진출을 타진할 수 있을 것"이라며 "국가 경쟁력 강화에도 이바지할 수 있다"고 말했다.
이번 연구는 한국정보화진흥원 국가중점 데이터 개방 사업의 하나인 '다국어 5종의 음성과 영어 대역문장 DB 구축 및 개방'으로 진행했다.
walden@yna.co.kr
(끝)
<저작권자(c) 연합뉴스, 무단 전재-재배포 금지>
한국전자통신연구원서 음성 데이터베이스 제작
(대전=연합뉴스) 이재림 기자 = 한국전자통신연구원(ETRI)은 국내에서 처음으로 태국어·말레이어·인도네시아어 음성 데이터베이스(DB)를 구축했다고 27일 밝혔다.
연구진은 최대한 많은 사람의 언어 자료를 얻기 위해 공개 의견수렴(크라우드 소싱·Crowd sourcing) 기법을 도입했다.
포인트 제공 방식으로 일반 사용자 참여를 유도한 결과 2만5천여 명이 발화에 나섰다.
단순히 양만 늘었을 뿐 아니라 정확도까지 확보했다.
서로 틀린 부분을 바로 잡아주는 집단 지성 덕분이다.
실제 외부 감리 업체 측정 결과 99% 이상의 높은 품질을 확인했다고 연구진은 설명했다.
ETRI는 아울러 기존보다 데이터양을 늘린 아랍어·베트남어 DB와 영어 대역문장(300만 발화)을 함께 만들었다.
대역문장은 원문 단어나 구절을 맞대어 번역해, 두 언어가 쌍을 이루도록 만들었다.
이 DB들은 인공지능(AI) 스피커·내비게이션·사물인터넷(IoT) 등 음성인식 시스템과 번역 소프트웨어 개발에 기초로 쓰일 예정이다.
예컨대 국내 포털 사이트를 비롯한 업체의 경우 DB 구축 비용을 기존보다 줄일 수 있을 것으로 ETRI는 보고 있다.
외국 업체 것을 사는 데 들어가는 비용의 5% 수준에서 DB를 제공할 방침이기 때문이다.
ETRI 음성지능연구그룹 윤 승 박사는 "이 DB를 통해 언어음성기술을 개발하면 다양한 외국 신규시장 진출을 타진할 수 있을 것"이라며 "국가 경쟁력 강화에도 이바지할 수 있다"고 말했다.
이번 연구는 한국정보화진흥원 국가중점 데이터 개방 사업의 하나인 '다국어 5종의 음성과 영어 대역문장 DB 구축 및 개방'으로 진행했다.
walden@yna.co.kr
(끝)
<저작권자(c) 연합뉴스, 무단 전재-재배포 금지>
관련뉴스










