



 코딩 없이 데이터 분석과 인공지능(AI) 모델링이 가능한 에이아이두 이지(AIDU ez)의 사용법을 배웠으니 이제는 실제로 적용해볼 차례다. 데이터 사이언스를 공부하는 사람이라면 한 번쯤 꼭 해본다는 타이타닉 승선자의 생존 여부 예측하기를 해보기로 했다.
코딩 없이 데이터 분석과 인공지능(AI) 모델링이 가능한 에이아이두 이지(AIDU ez)의 사용법을 배웠으니 이제는 실제로 적용해볼 차례다. 데이터 사이언스를 공부하는 사람이라면 한 번쯤 꼭 해본다는 타이타닉 승선자의 생존 여부 예측하기를 해보기로 했다.분석할 데이터 파일에는 승선자 891명의 정보가 담겨 있다. 승선자 번호와 이름, 성별, 객실 등급, 나이, 동승자 수, 운임, 탑승지 등이다. 가장 중요한 생존 여부도 함께 기록됐다. 우리가 맞혀야 하는 ‘생존 여부’가 레이블(label)이고, 그 외의 정보들은 생존 여부에 영향을 미치는 피처(feature)다. 데이터를 분석해 생존에 영향을 주는 데이터와 그렇지 않은 데이터를 솎아내는 게 먼저 해야 할 일이다.
에이아이두 이지에서 데이터를 업로드하고 ‘기초 정보 분석’에 들어가면 항목별 데이터를 볼 수 있다. 승선자 번호를 보면 중복되지 않는 값(distinct)이 891로 승선자 수와 같다. ‘데이터 샘플 보기’를 보면 승선자 번호는 열마다 붙어 있는 번호라는 사실을 알 수 있다. 당연히 생존에는 아무런 영향을 주지 않을 것이다.
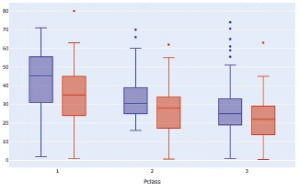
조금 더 자료를 구체적으로 보기 위해 데이터 시각화를 해보기로 했다. 변수별 상관관계를 볼 수 있는 히트맵을 선택하자 운임과 생존 관계는 약한 양의 상관관계를, 반대로 연령과 객실 등급은 생존과 음의 상관관계를 보였다. 쉽게 말해 비싼 표를 샀거나 어릴수록 살 확률이 높다는 얘기다.
AI 모델링을 시작하기 전에 하자가 있는 데이터를 보완해야 한다. 나이 데이터는 아무런 정보가 입력되지 않은 결측값(missing)이 177개나 되기 때문에 AI 학습 과정에서 문제가 생긴다. 먼저 ‘데이터 가공’ 탭에서 비어 있는 숫자를 채워주면 된다. 평균값(mean)은 29.699로 정수가 아니기 때문에 대신 중간값(median)인 28로 채워 넣었다.
마지막으로 AI 모델 학습을 진행할 차례다. ‘AI 모델 학습’ 탭에서 여러 변수 가운데 인풋 칼럼, 아웃풋 칼럼, 제외 칼럼을 골라내면 된다. 생존 여부를 결과로 놓고 승선자 번호, 이름, 탑승지 등은 제외한다. ‘학습 시작’ 버튼을 누르면 자동으로 학습을 시작한다. 정밀도(accuracy)는 0.822가 나왔다. 학습을 통해 만들어진 AI 모델로 생존 여부를 예측했을 때 82.2%의 확률로 정답을 맞혔다는 의미다. ‘AI 활용’ 탭에선 학습시킨 모델을 이용해 새로운 변수에 대한 결과를 예측할 수 있다. 1등급 객실과 여성, 나이 7세를 선택하자 AI는 87.7%의 확률로 생존했을 것이란 답을 내놨다. (⑤에서 계속)
이승우 기자 leeswoo@hankyung.com
관련뉴스










