



오픈AI의 챗GPT와 같은 생성 인공지능(AI)이 온라인상의 ‘가비지(쓰레기) 데이터’를 폭증시킬 수 있다는 우려가 나온다. 전문가도 속일 만한 글짓기 실력을 갖추고 있지만 한정된 데이터 안에서만 결과물을 낸다는 한계 때문이다. 챗GPT가 작성한 글의 참·거짓을 확인하기 어렵다는 점도 챗GPT 활용에 앞서 염두에 둬야 하는 부분이다.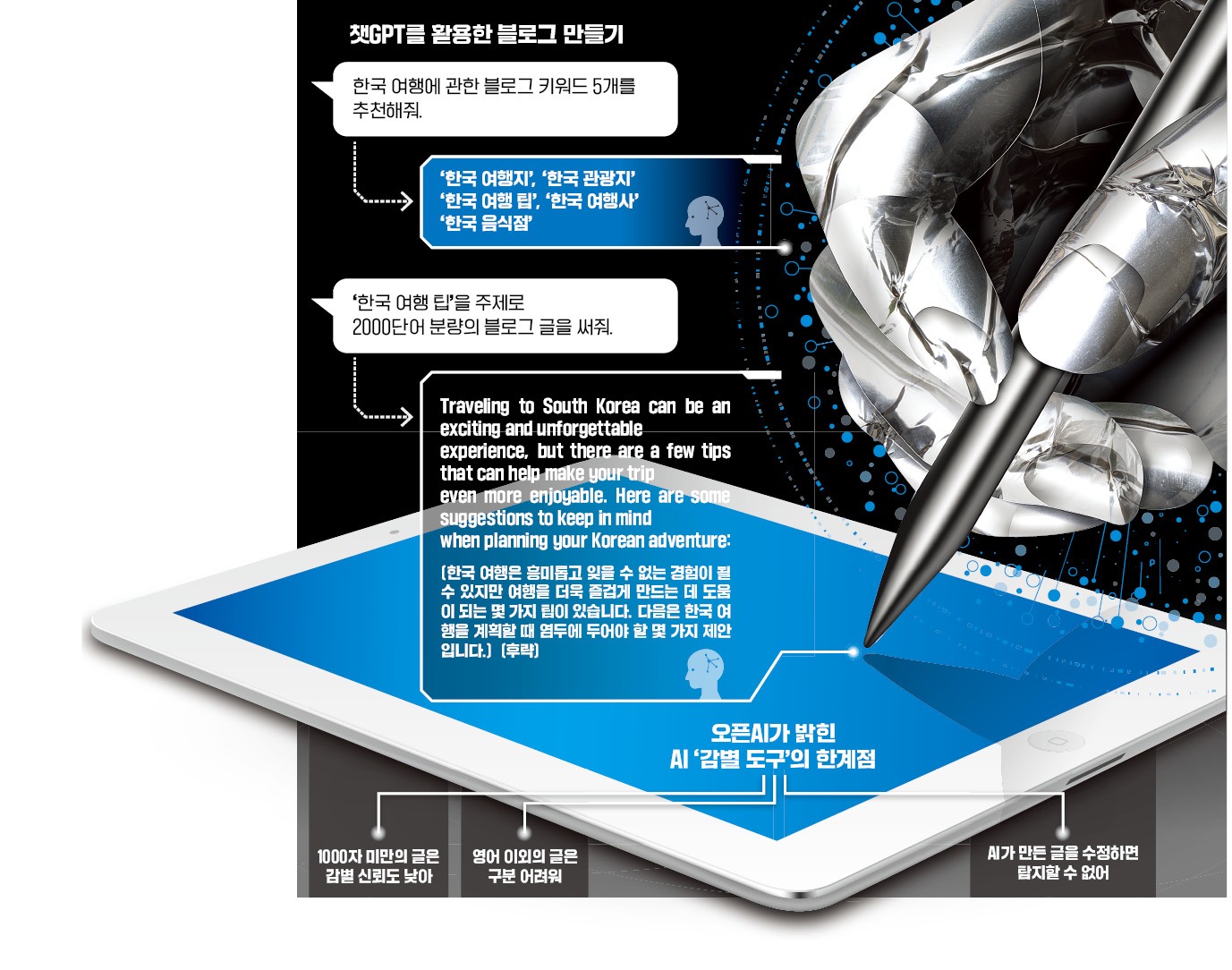
7일 정보기술(IT)업계에 따르면 최근 포털 사이트나 유튜브에서 챗GPT로 돈 버는 방법을 공유하는 콘텐츠를 쉽게 찾아볼 수 있다. 유튜브에서 챗GPT를 검색하면 ‘돈 벌기’ ‘to make money’와 같은 연관 검색어가 뜰 정도다. 챗GPT로 블로그 주제를 선정해 영어로 글을 쓴 뒤 블로그에 붙여넣어 광고 수익을 거둘 수 있다는 내용이 대부분이다. 챗GPT와 이미지 생성 AI를 함께 활용해 유튜브 영상을 만드는 시도도 이어지고 있다.
과거에도 사람들이 자주 찾는 검색어만 모은 무의미한 인터넷 페이지를 만들어 광고를 붙이거나 피싱 사이트로 유도하는 사례가 흔했다. 하지만 챗GPT를 활용하면 사람이 쓴 것과 별반 차이나지 않는 글을 만들 수 있다는 점이 다르다. 검색한 사람은 이 글을 사람이 썼는지, AI가 작성했는지 구분할 방법이 없다. 챗GPT의 특성상 정보의 사실 여부를 검증하기도 어렵다.
AI가 만든 데이터를 활용해 AI를 학습시킬 경우 성능이 떨어진다는 연구 결과도 나왔다. 일본 이화학연구소의 하타야 류이치로 연구팀은 최근 AI가 생성한 이미지를 학습 데이터에 포함한 비중이 높아질수록 성능이 저하된다는 내용의 연구 결과를 발표했다. 원본 이미지로만 학습한 AI가 만든 1000개의 이미지 중 75.6%는 이전에 보지 못한 새로운 이미지였다. AI 생성 이미지가 80%인 경우 65.3%로 비중이 감소했다. AI 이미지와 실제 모습 간 차이가 심해지는 등 품질도 낮아졌다.
이 때문에 챗GPT와 같은 생성 AI가 활성화될수록 온라인 공간에 가비지 데이터가 기하급수적으로 늘어날 수 있다는 우려도 나온다. 사람보다 빠른 속도로 콘텐츠를 만들 수 있는 만큼 앞으로 몇 년 뒤면 온라인 공간이 AI가 만든 콘텐츠로 뒤덮일 수 있다는 얘기다. 영국의 AI 전문가 니나 시크는 지난달 미국에서 열린 CES 2023의 토론회에서 “2025년까지 콘텐츠의 90%가 생성 AI의 도움을 받아 제작될 것”이라고 전망했다.
이 때문에 생성 AI의 오남용을 막기 위한 적절한 규제와 안전장치가 필요하다는 지적도 나온다. 오픈AI의 미라 무라티 최고기술책임자는 최근 미국 타임지와의 인터뷰에서 “챗GPT도 나쁜 의도로 악용될 수 있다”며 “이 기술이 가져올 영향력을 고려할 때 정부, 철학자 등 모두가 참여해 규제를 논의해야 한다”고 말했다.
새로운 기술이 도입되는 과도기에 필수적으로 뒤따르는 일시적 혼란이라는 의견도 있다. 자동차가 등장한 이후 시간이 지나면서 도로가 정비되고 관련 제도가 만들어진 것처럼 자연스럽게 해결될 문제란 얘기다. 배순민 KT AI2XL 소장은 “AI는 주어진 데이터를 비판적으로 보지 않는다”며 “기업이 믿을 만한 AI를 만드는 것은 물론 이용자 각자가 온라인의 정보를 비판적으로 보는 디지털 리터러시를 길러야 할 필요가 있다”고 조언했다.
이승우 기자 leeswoo@hankyung.com
“챗GPT로 돈 버는 법 공유합니다”
7일 정보기술(IT)업계에 따르면 최근 포털 사이트나 유튜브에서 챗GPT로 돈 버는 방법을 공유하는 콘텐츠를 쉽게 찾아볼 수 있다. 유튜브에서 챗GPT를 검색하면 ‘돈 벌기’ ‘to make money’와 같은 연관 검색어가 뜰 정도다. 챗GPT로 블로그 주제를 선정해 영어로 글을 쓴 뒤 블로그에 붙여넣어 광고 수익을 거둘 수 있다는 내용이 대부분이다. 챗GPT와 이미지 생성 AI를 함께 활용해 유튜브 영상을 만드는 시도도 이어지고 있다.
과거에도 사람들이 자주 찾는 검색어만 모은 무의미한 인터넷 페이지를 만들어 광고를 붙이거나 피싱 사이트로 유도하는 사례가 흔했다. 하지만 챗GPT를 활용하면 사람이 쓴 것과 별반 차이나지 않는 글을 만들 수 있다는 점이 다르다. 검색한 사람은 이 글을 사람이 썼는지, AI가 작성했는지 구분할 방법이 없다. 챗GPT의 특성상 정보의 사실 여부를 검증하기도 어렵다.
AI가 만든 데이터를 활용해 AI를 학습시킬 경우 성능이 떨어진다는 연구 결과도 나왔다. 일본 이화학연구소의 하타야 류이치로 연구팀은 최근 AI가 생성한 이미지를 학습 데이터에 포함한 비중이 높아질수록 성능이 저하된다는 내용의 연구 결과를 발표했다. 원본 이미지로만 학습한 AI가 만든 1000개의 이미지 중 75.6%는 이전에 보지 못한 새로운 이미지였다. AI 생성 이미지가 80%인 경우 65.3%로 비중이 감소했다. AI 이미지와 실제 모습 간 차이가 심해지는 등 품질도 낮아졌다.
이 때문에 챗GPT와 같은 생성 AI가 활성화될수록 온라인 공간에 가비지 데이터가 기하급수적으로 늘어날 수 있다는 우려도 나온다. 사람보다 빠른 속도로 콘텐츠를 만들 수 있는 만큼 앞으로 몇 년 뒤면 온라인 공간이 AI가 만든 콘텐츠로 뒤덮일 수 있다는 얘기다. 영국의 AI 전문가 니나 시크는 지난달 미국에서 열린 CES 2023의 토론회에서 “2025년까지 콘텐츠의 90%가 생성 AI의 도움을 받아 제작될 것”이라고 전망했다.
“악용 가능성 있어…규제 논의해야”
AI가 생성한 콘텐츠를 구분하기 위한 AI도 등장하고 있다. 오픈AI는 지난달 31일 챗GPT가 작성한 글을 찾아내는 AI를 내놨다. 챗GPT를 활용해 과제를 제출하는 등 사회적 논란이 불거진 데 따른 것이다. 웹사이트에서 글을 붙여넣은 뒤 제출 버튼을 누르면 AI의 작성 여부를 ‘매우 높음’ ‘불확실’ ‘가능성 없음’ 등으로 평가한다. 하지만 아직 성능이 떨어진다. 오픈AI에 따르면 이 도구의 성공률은 26%에 불과하다. 훈련을 더 거치면 정확도가 높아질 수 있다고 하지만 현재로선 4건 중 3건을 틀리는 셈이다.이 때문에 생성 AI의 오남용을 막기 위한 적절한 규제와 안전장치가 필요하다는 지적도 나온다. 오픈AI의 미라 무라티 최고기술책임자는 최근 미국 타임지와의 인터뷰에서 “챗GPT도 나쁜 의도로 악용될 수 있다”며 “이 기술이 가져올 영향력을 고려할 때 정부, 철학자 등 모두가 참여해 규제를 논의해야 한다”고 말했다.
새로운 기술이 도입되는 과도기에 필수적으로 뒤따르는 일시적 혼란이라는 의견도 있다. 자동차가 등장한 이후 시간이 지나면서 도로가 정비되고 관련 제도가 만들어진 것처럼 자연스럽게 해결될 문제란 얘기다. 배순민 KT AI2XL 소장은 “AI는 주어진 데이터를 비판적으로 보지 않는다”며 “기업이 믿을 만한 AI를 만드는 것은 물론 이용자 각자가 온라인의 정보를 비판적으로 보는 디지털 리터러시를 길러야 할 필요가 있다”고 조언했다.
이승우 기자 leeswoo@hankyung.com
관련뉴스










