



라인 "세계 최대규모 AI 음성 신호처리 학회서 논문 8편 채택"
자연스러운 '감정 음성' 합성·여러 목소리 가려내는 기술
(서울=연합뉴스) 임성호 기자 = 라인은 세계 최대 규모 인공지능(AI) 음성·음향·신호처리 학술대회인 'ICASSP 2023'에서 논문 8편이 채택됐다고 14일 밝혔다.
올해 48회차를 맞은 이 학회는 국제전기전자협회 신호처리학회(IEEE Signal Processing Society)가 주최한다.
채택된 논문 8편 가운데 6편은 라인이 주저자로 참여했다. 이 학회에 채택된 논문 중 라인이 주저자인 경우는 지난해 3편에서 두 배 늘었다.
2편은 각각 일본 도쿄도립대, 와세다대와 공동 집필한 논문이며, 모두 학회 개최 기간인 오는 6월 4∼10일 발표한다.
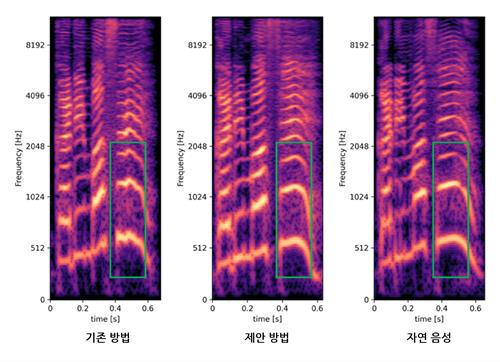
이번에 채택된 논문에는 감정 음성 합성 시 텍스트에서 음성 파형으로 변환하는 과정에서 음성 피치(높이) 정보를 이용하는 엔드투엔드(End-to-End) 모델 관련 제안이 소개됐다.
기존 모델은 풍부한 표현이 필요한 감정 음성 합성 시 자연스러운 음성을 합성하기 어려운 사례가 많았으나, 변환 과정을 단일 모델로 수행하는 엔드투엔드 모델은 양질의 음성을 만들 수 있다고 라인은 설명했다.
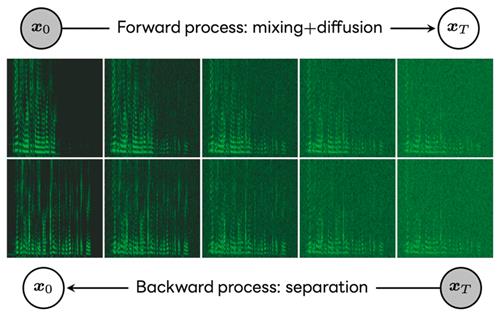
또 다른 논문에서는 다수 화자가 혼재된 음성을 가려내는 음원 분리 시 이미지 생성에 활용되는 '확산 모델'(디퓨전)을 이용하는 방식을 다뤘다.
머신러닝을 이용하는 기존의 음원 분리는 교사 데이터의 음성 분리도를 극대화하는 식별 모델을 이용하는 방식이 주류였으나, 사람이 듣기에 부자연스러운 경우가 종종 있었다.
확산 모델을 활용한 결과 분리음의 왜곡이 줄어들어 인간 지각 능력에 기반한 음성 품질 평가 지표(DNSMOS)에서 기존 방법보다 뛰어난 결과를 냈다고 라인은 덧붙였다.
라인은 "AI 기술을 활용해 새로운 서비스를 창출하는 동시에 연구·개발에도 적극 투자하고 있다"면서 "AI 기술 기초 연구를 적극 추진해 기존 서비스의 품질 향상은 물론 새로운 기능 및 서비스 창출에 노력을 기울일 예정"이라고 말했다.
sh@yna.co.kr
(끝)
<저작권자(c) 연합뉴스, 무단 전재-재배포 금지>
자연스러운 '감정 음성' 합성·여러 목소리 가려내는 기술
(서울=연합뉴스) 임성호 기자 = 라인은 세계 최대 규모 인공지능(AI) 음성·음향·신호처리 학술대회인 'ICASSP 2023'에서 논문 8편이 채택됐다고 14일 밝혔다.
올해 48회차를 맞은 이 학회는 국제전기전자협회 신호처리학회(IEEE Signal Processing Society)가 주최한다.
채택된 논문 8편 가운데 6편은 라인이 주저자로 참여했다. 이 학회에 채택된 논문 중 라인이 주저자인 경우는 지난해 3편에서 두 배 늘었다.
2편은 각각 일본 도쿄도립대, 와세다대와 공동 집필한 논문이며, 모두 학회 개최 기간인 오는 6월 4∼10일 발표한다.
이번에 채택된 논문에는 감정 음성 합성 시 텍스트에서 음성 파형으로 변환하는 과정에서 음성 피치(높이) 정보를 이용하는 엔드투엔드(End-to-End) 모델 관련 제안이 소개됐다.
기존 모델은 풍부한 표현이 필요한 감정 음성 합성 시 자연스러운 음성을 합성하기 어려운 사례가 많았으나, 변환 과정을 단일 모델로 수행하는 엔드투엔드 모델은 양질의 음성을 만들 수 있다고 라인은 설명했다.
또 다른 논문에서는 다수 화자가 혼재된 음성을 가려내는 음원 분리 시 이미지 생성에 활용되는 '확산 모델'(디퓨전)을 이용하는 방식을 다뤘다.
머신러닝을 이용하는 기존의 음원 분리는 교사 데이터의 음성 분리도를 극대화하는 식별 모델을 이용하는 방식이 주류였으나, 사람이 듣기에 부자연스러운 경우가 종종 있었다.
확산 모델을 활용한 결과 분리음의 왜곡이 줄어들어 인간 지각 능력에 기반한 음성 품질 평가 지표(DNSMOS)에서 기존 방법보다 뛰어난 결과를 냈다고 라인은 덧붙였다.
라인은 "AI 기술을 활용해 새로운 서비스를 창출하는 동시에 연구·개발에도 적극 투자하고 있다"면서 "AI 기술 기초 연구를 적극 추진해 기존 서비스의 품질 향상은 물론 새로운 기능 및 서비스 창출에 노력을 기울일 예정"이라고 말했다.
sh@yna.co.kr
(끝)
<저작권자(c) 연합뉴스, 무단 전재-재배포 금지>
관련뉴스










