



바둑 실력만이 아니라 AI 발전 수준 보여준 '알파고'
'딥러닝' 가능케한 컴퓨터 능력, 학습데이터 축적 중요
'문제해결 대회'로 동기 부여…정부는 '키다리아저씨'역할
김석원 < 소프트웨어정책연구소 SW융합정책실장 >
인공지능 알파고 충격의 시사점
 지난 9일부터 15일까지 서울 포시즌스호텔에서 열린 이세돌 9단과 구글 인공지능(AI) 바둑프로그램 알파고의 ‘구글 딥마인드 챌린지 매치’를 보면서 나도 모르게 심장이 뛰고 가슴이 아팠다. 알파고 논문을 분석했고, 인공지능 연구에 대해 모르는 것도 아니며, 내기도 알파고 쪽에 건 내가 이럴 정도니 일반인은 오죽했을까 싶다.
지난 9일부터 15일까지 서울 포시즌스호텔에서 열린 이세돌 9단과 구글 인공지능(AI) 바둑프로그램 알파고의 ‘구글 딥마인드 챌린지 매치’를 보면서 나도 모르게 심장이 뛰고 가슴이 아팠다. 알파고 논문을 분석했고, 인공지능 연구에 대해 모르는 것도 아니며, 내기도 알파고 쪽에 건 내가 이럴 정도니 일반인은 오죽했을까 싶다.
돌아보니 원인은 이 9단의 표정에 있었다. 최선을 다하는, 고뇌에 쌓인 이 9단의 얼굴에 공감하며 잠깐 인간과 기계의 대결에 들어가 인간 편 응원단이 됐던 것이다. 알파고의 승리는 인간의 승리다.
이번 알파고 벤치마크 테스트를 통해 인간을 더 편하게 하고 덜 아프게 할 수 있는 기술의 작은 성취를 확인한 것이다. 바둑만큼 복잡하고 다양한 요소를 고려하는 의사 결정 과정은 인공지능 소프트웨어에 맡기고 우리는 결과를 검사하고 창의적 아이디어를 내는 역할을 하는 때가 가까워졌다. 알파고 덕분에 암 극복이 빨라지고 신약 개발에도 도움이 된다면 알파고가 이 9단을 이긴 것은 충격이 아니라 감탄이어야 하지 않을까?
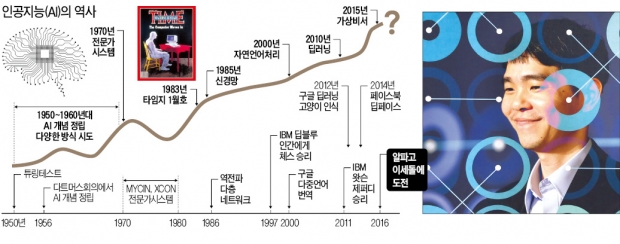
인공지능은 이 단어의 정서적 울림 때문에 처음부터 너무 큰 기대와 그 뒤를 따르는 외면을 겪으며 조금씩 발전해 왔다. 컴퓨터가 발명되자마자 연구자들은 인공지능을 연구하기 시작했고 금방 내놓을 수 있을 줄 알았다. 그러나 수년간의 다양한 시도 끝에 예상보다 어려운 문제라는 것이 알려지자 관심은 급속도로 식었다. 전문가가 가진 지식을 규칙의 형태로 표현하고 추론하는 전문가시스템이 등장했을 때와 신경망 학습을 위한 ‘역전파 알고리즘’이 발명됐을 때도 같은 일이 반복됐다. 신경망을 학습시키는 확장성의 한계로 다시 암흑기이던 때가 1990년대부터 최근까지다.
‘딥러닝’이 AI 부흥 이끌어
조용히 연구하던 몇 명의 연구자가 이론적으로 이 제약을 넘어설 방안을 제시했고, 좀 더 시간이 지나 컴퓨터 성능이 충분하고 대용량 학습데이터가 축적되자 구글과 페이스북이 커다란 신경망으로 실용적 수준의 결과를 낼 수 있다는 것을 대중에게 보여줬다. 이것이 대형 신경망 학습방법인 ‘딥러닝’으로 인공지능의 새로운 부흥기를 이끌고 있다.
인터넷 검색 품질을 높이기 위해 자연어 처리와 지식 표현 등 인간의 지식을 표현하고, 이것을 활용해 추론하는 기호형 인공지능의 연구개발이 꾸준히 이뤄졌다. 애플의 지능형 개인에이전트 ‘시리’가 이 시기의 연구에 기반한 기술이다. 그러나 기호형 인공지능의 성능이 일반에 널리 알려진 계기는 IBM 인공지능 슈퍼컴퓨터 ‘왓슨’의 제퍼디퀴즈대회 우승이다.
알파고의 의미는 바둑 자체에 있는 것이 아니라 기호형 인공지능에서 오랫동안 개발해 온 방법에 딥러닝을 사용한 신경망을 결합하면 품질이 향상될 수 있음을 보여준 것이다. 알파고 추론의 기본 구조는 오래전 고안된 기호형 인공지능의 게임트리 탐색기술이다. 알파고에서 개선된 점은 과거에 ‘휴리스틱(heuristics)’이라는 주관적 계산 결과에 따라 탐색하던 부분을 ‘정책망’이나 ‘가치망’이라는 신경망을 이용해 데이터에 기반해서 더 정확하게 계산하도록 한 것이다. 휴리스틱은 인공지능의 논리 추론, 계획 수립 등 많은 분야에서 사용되기 때문에 딥러닝이 유행하면서 인공지능을 연구하는 여러 곳에서 이런 시도를 하고 있을 것이다. 지금은 기호형 인공지능과 신경망이 서로 경쟁하는 시대가 아니라 통합하는 시대이고 이것을 눈앞에 보여준 것이 알파고다.
알파고와 왓슨의 사례는 인공지능 연구가 제한된 실험실 환경 대신 현실의 구체적 목표를 해결하는 과정에서 발전한다는 것을 보여준다. 미국 정부의 방위고등연구계획국(DARPA) 그랜드 챌린지는 자율주행자동차 실현을 앞당겼다. 캐글닷컴(Kaggle.com)에서는 현실의 문제와 데이터를 제공하고 우승자를 포상하는 문제 해결 콘테스트를 열어 연구자에게 동기를 주면서 기술 발전을 촉진하고 있다. 또 공개 소프트웨어 문화와 데이터 공유를 통해 외부의 창의력을 흡수하고 고급 인재를 구하는 목표를 추구한다. 구글의 텐서플로, 마이크로소프트의 CNTK, 페이스북의 FAIR 등 딥러닝 관련 소프트웨어의 공개는 외부 개발자 참여를 통해 소프트웨어 품질을 개선하고, 이런 활동을 통해 좋은 인재를 먼저 발탁하려는 치열한 경쟁의 표시다. 기업의 경쟁력은 소스코드에 있는 것이 아니라 이것을 개발한 인재와 기업에 축적된 데이터, 조직 내 시스템이 경쟁력이라는 것을 체감하고 있기 때문에 가능한 일이다.
데이터 공유 통해 창의력 흡수
인공지능 연구를 위해서는 필요할 때 강력한 컴퓨팅 파워를 쓸 수 있는 환경도 필요하다. 현실적 문제를 다루기 위해 많은 데이터를 학습하고 처리하려면 충분한 규모의 컴퓨팅 파워가 중요하다. 알파고는 구글 인프라를 사용해 고성능 분산처리 시스템으로 구현됐고 왓슨도 여러 대의 컴퓨터를 이용해 제퍼디퀴즈대회에 참가했다.
알파고 덕에 정부와 국민 모두 인공지능에 대한 관심이 높아진 것은 긍정적이다. 이 여세를 몰아 정부는 인공지능 기술 육성에 나서기로 했다. 중요한 것은 과거와는 다른 방식으로 접근해야 한다는 것이다. 연구는 정부 주도가 아니라 민간 주도로 하도록 놔두고, 정부는 연구 지원 환경을 제대로 조성하는 데 집중해야 한다.
소프트웨어 인프라를 위해 공개 데이터를 많이 확보하고 생성해서 공유하고, 강력한 컴퓨팅 파워를 갖추기 어려운 중소기업과 연구그룹이 편리하게 쓸 수 있는 고성능 컴퓨팅 서비스를 지원하는 등이 정부가 제대로 해야 하는 사업이다. 이렇게 해서 나중에 누군가 성공했을 때 정부는 한 일이 거의 없는 것 같은 인상이 남는 ‘키다리아저씨 역할’만 수행하는 것이다.
새 연구소, 다른 모습 보여야
이번 알파고 이벤트에 맞춰 정부는 삼성전자 LG전자 SK텔레콤 KT 네이버 현대자동차와 함께 ‘지능정보기술연구소’를 설립하고, 인공지능 연구에 막대한 예산을 투입하기로 했다. 걱정의 소리가 없는 것은 아니다. 무슨 일만 생기면 새 조직을 구성한다는 냉소적 반응도 과거 사례를 돌아보면 이해 안 되는 것도 아니다. 새로 생기는 연구소가 기존 연구소와 확실하게 다른 모습을 보여줘야 이런 비난을 칭찬으로 바꾸고 국내 인공지능 기술 발전에 이바지할 수 있다.
연구원 계약제, 과제 기간이 끝나면 연구원도 함께 계약이 끝나는 프로젝트 일몰제, 연구팀 자율성 등 최소한의 변화된 형태를 새 연구소에서 보여주기를 기대한다. 정부 예산이 투입되는 새 연구소가 과거와 같은 형태를 벗어나지 못한다면 냉소는 사실로 바뀌고, 인공지능은 제자리걸음이고, 세금만 쓰는 연구소만 하나 더 남게 될 것이다.
김석원 < 소프트웨어정책연구소 SW융합정책실장 >
[한경닷컴 바로가기] [스내커] [한경+ 구독신청] ⓒ '성공을 부르는 습관' 한경닷컴, 무단 전재 및 재배포 금지
'딥러닝' 가능케한 컴퓨터 능력, 학습데이터 축적 중요
'문제해결 대회'로 동기 부여…정부는 '키다리아저씨'역할
김석원 < 소프트웨어정책연구소 SW융합정책실장 >
인공지능 알파고 충격의 시사점
지난 9일부터 15일까지 서울 포시즌스호텔에서 열린 이세돌 9단과 구글 인공지능(AI) 바둑프로그램 알파고의 ‘구글 딥마인드 챌린지 매치’를 보면서 나도 모르게 심장이 뛰고 가슴이 아팠다. 알파고 논문을 분석했고, 인공지능 연구에 대해 모르는 것도 아니며, 내기도 알파고 쪽에 건 내가 이럴 정도니 일반인은 오죽했을까 싶다.돌아보니 원인은 이 9단의 표정에 있었다. 최선을 다하는, 고뇌에 쌓인 이 9단의 얼굴에 공감하며 잠깐 인간과 기계의 대결에 들어가 인간 편 응원단이 됐던 것이다. 알파고의 승리는 인간의 승리다.
이번 알파고 벤치마크 테스트를 통해 인간을 더 편하게 하고 덜 아프게 할 수 있는 기술의 작은 성취를 확인한 것이다. 바둑만큼 복잡하고 다양한 요소를 고려하는 의사 결정 과정은 인공지능 소프트웨어에 맡기고 우리는 결과를 검사하고 창의적 아이디어를 내는 역할을 하는 때가 가까워졌다. 알파고 덕분에 암 극복이 빨라지고 신약 개발에도 도움이 된다면 알파고가 이 9단을 이긴 것은 충격이 아니라 감탄이어야 하지 않을까?
인공지능은 이 단어의 정서적 울림 때문에 처음부터 너무 큰 기대와 그 뒤를 따르는 외면을 겪으며 조금씩 발전해 왔다. 컴퓨터가 발명되자마자 연구자들은 인공지능을 연구하기 시작했고 금방 내놓을 수 있을 줄 알았다. 그러나 수년간의 다양한 시도 끝에 예상보다 어려운 문제라는 것이 알려지자 관심은 급속도로 식었다. 전문가가 가진 지식을 규칙의 형태로 표현하고 추론하는 전문가시스템이 등장했을 때와 신경망 학습을 위한 ‘역전파 알고리즘’이 발명됐을 때도 같은 일이 반복됐다. 신경망을 학습시키는 확장성의 한계로 다시 암흑기이던 때가 1990년대부터 최근까지다.
‘딥러닝’이 AI 부흥 이끌어
조용히 연구하던 몇 명의 연구자가 이론적으로 이 제약을 넘어설 방안을 제시했고, 좀 더 시간이 지나 컴퓨터 성능이 충분하고 대용량 학습데이터가 축적되자 구글과 페이스북이 커다란 신경망으로 실용적 수준의 결과를 낼 수 있다는 것을 대중에게 보여줬다. 이것이 대형 신경망 학습방법인 ‘딥러닝’으로 인공지능의 새로운 부흥기를 이끌고 있다.
인터넷 검색 품질을 높이기 위해 자연어 처리와 지식 표현 등 인간의 지식을 표현하고, 이것을 활용해 추론하는 기호형 인공지능의 연구개발이 꾸준히 이뤄졌다. 애플의 지능형 개인에이전트 ‘시리’가 이 시기의 연구에 기반한 기술이다. 그러나 기호형 인공지능의 성능이 일반에 널리 알려진 계기는 IBM 인공지능 슈퍼컴퓨터 ‘왓슨’의 제퍼디퀴즈대회 우승이다.
알파고의 의미는 바둑 자체에 있는 것이 아니라 기호형 인공지능에서 오랫동안 개발해 온 방법에 딥러닝을 사용한 신경망을 결합하면 품질이 향상될 수 있음을 보여준 것이다. 알파고 추론의 기본 구조는 오래전 고안된 기호형 인공지능의 게임트리 탐색기술이다. 알파고에서 개선된 점은 과거에 ‘휴리스틱(heuristics)’이라는 주관적 계산 결과에 따라 탐색하던 부분을 ‘정책망’이나 ‘가치망’이라는 신경망을 이용해 데이터에 기반해서 더 정확하게 계산하도록 한 것이다. 휴리스틱은 인공지능의 논리 추론, 계획 수립 등 많은 분야에서 사용되기 때문에 딥러닝이 유행하면서 인공지능을 연구하는 여러 곳에서 이런 시도를 하고 있을 것이다. 지금은 기호형 인공지능과 신경망이 서로 경쟁하는 시대가 아니라 통합하는 시대이고 이것을 눈앞에 보여준 것이 알파고다.
알파고와 왓슨의 사례는 인공지능 연구가 제한된 실험실 환경 대신 현실의 구체적 목표를 해결하는 과정에서 발전한다는 것을 보여준다. 미국 정부의 방위고등연구계획국(DARPA) 그랜드 챌린지는 자율주행자동차 실현을 앞당겼다. 캐글닷컴(Kaggle.com)에서는 현실의 문제와 데이터를 제공하고 우승자를 포상하는 문제 해결 콘테스트를 열어 연구자에게 동기를 주면서 기술 발전을 촉진하고 있다. 또 공개 소프트웨어 문화와 데이터 공유를 통해 외부의 창의력을 흡수하고 고급 인재를 구하는 목표를 추구한다. 구글의 텐서플로, 마이크로소프트의 CNTK, 페이스북의 FAIR 등 딥러닝 관련 소프트웨어의 공개는 외부 개발자 참여를 통해 소프트웨어 품질을 개선하고, 이런 활동을 통해 좋은 인재를 먼저 발탁하려는 치열한 경쟁의 표시다. 기업의 경쟁력은 소스코드에 있는 것이 아니라 이것을 개발한 인재와 기업에 축적된 데이터, 조직 내 시스템이 경쟁력이라는 것을 체감하고 있기 때문에 가능한 일이다.
데이터 공유 통해 창의력 흡수
인공지능 연구를 위해서는 필요할 때 강력한 컴퓨팅 파워를 쓸 수 있는 환경도 필요하다. 현실적 문제를 다루기 위해 많은 데이터를 학습하고 처리하려면 충분한 규모의 컴퓨팅 파워가 중요하다. 알파고는 구글 인프라를 사용해 고성능 분산처리 시스템으로 구현됐고 왓슨도 여러 대의 컴퓨터를 이용해 제퍼디퀴즈대회에 참가했다.
알파고 덕에 정부와 국민 모두 인공지능에 대한 관심이 높아진 것은 긍정적이다. 이 여세를 몰아 정부는 인공지능 기술 육성에 나서기로 했다. 중요한 것은 과거와는 다른 방식으로 접근해야 한다는 것이다. 연구는 정부 주도가 아니라 민간 주도로 하도록 놔두고, 정부는 연구 지원 환경을 제대로 조성하는 데 집중해야 한다.
소프트웨어 인프라를 위해 공개 데이터를 많이 확보하고 생성해서 공유하고, 강력한 컴퓨팅 파워를 갖추기 어려운 중소기업과 연구그룹이 편리하게 쓸 수 있는 고성능 컴퓨팅 서비스를 지원하는 등이 정부가 제대로 해야 하는 사업이다. 이렇게 해서 나중에 누군가 성공했을 때 정부는 한 일이 거의 없는 것 같은 인상이 남는 ‘키다리아저씨 역할’만 수행하는 것이다.
새 연구소, 다른 모습 보여야
이번 알파고 이벤트에 맞춰 정부는 삼성전자 LG전자 SK텔레콤 KT 네이버 현대자동차와 함께 ‘지능정보기술연구소’를 설립하고, 인공지능 연구에 막대한 예산을 투입하기로 했다. 걱정의 소리가 없는 것은 아니다. 무슨 일만 생기면 새 조직을 구성한다는 냉소적 반응도 과거 사례를 돌아보면 이해 안 되는 것도 아니다. 새로 생기는 연구소가 기존 연구소와 확실하게 다른 모습을 보여줘야 이런 비난을 칭찬으로 바꾸고 국내 인공지능 기술 발전에 이바지할 수 있다.
연구원 계약제, 과제 기간이 끝나면 연구원도 함께 계약이 끝나는 프로젝트 일몰제, 연구팀 자율성 등 최소한의 변화된 형태를 새 연구소에서 보여주기를 기대한다. 정부 예산이 투입되는 새 연구소가 과거와 같은 형태를 벗어나지 못한다면 냉소는 사실로 바뀌고, 인공지능은 제자리걸음이고, 세금만 쓰는 연구소만 하나 더 남게 될 것이다.
김석원 < 소프트웨어정책연구소 SW융합정책실장 >
[한경닷컴 바로가기] [스내커] [한경+ 구독신청] ⓒ '성공을 부르는 습관' 한경닷컴, 무단 전재 및 재배포 금지
관련뉴스










