지난 주요뉴스 한국경제TV에서 선정한 지난 주요뉴스 뉴스썸 한국경제TV 웹사이트에서 접속자들이 많이 본 뉴스 한국경제TV 기사만 onoff
-
TTA, AI 학습용 데이터에서 유해 표현 찾는 AI 모델 공개 2025-02-03 11:50:52
프로그래밍 인터페이스(API)를 활용하면 누구나 말뭉치 텍스트의 유해성을 분석하고 유해 표현을 정제할 수 있다. 손승현 한국정보통신기술협회장은 "AI 모델은 배운 대로 텍스트를 생성하기 때문에 학습용 텍스트에 포함된 유해 표현을 정제하는 과정이 꼭 필요하다"고 말했다. csm@yna.co.kr (끝) <저작권자(c) 연합뉴스,...
- 뉴스 > 경제
- 바로가기

-
유클리드소프트, 2024년 ‘화학물질 위험성 예측 데이터’ 구축 사업 성료 2024-12-27 10:13:29
데이터 5286만 건과 초거대AI 학습을 위한 말뭉치 데이터 3억 토큰을 구축했으며 2022년에는 ‘인공지능 학습용 데이터 구축 사업’ 최종 평가에서‘대규모 시각 추론 학습 데이터’가 우수 등급을 받는 등 데이터 구축 분야의 전문성을 인정받고 있다. 2024년 ‘초거대AI 확산 생태계 조성사업’에서도 ‘화학물질 위험성...
- 뉴스 > 산업
- 바로가기

-
케이경제문화, 한국어 AI 학습 앱 개발...외국인 전용 웹 포털 구축 2024-12-23 08:00:03
AI 한국어 학습 앱은 ‘학습자 말뭉치(외국인이 한국어를 학습하면서 만들어 낸 한국어 자료를 데이터화한 자료)’를 교육 과정에 맞춰 효율적으로 학습할 수 있도록 가공한 프로그램이다. 외국인 한국어를 발음하거나 문장을 쓰면 문장이나 맥락에 오류가 있는지 실시간 확인해 수정할 수 있도록 도와준다. 이 회사는 국내...
- 뉴스 > 생활문화
- 바로가기

-
"특화 AI 서비스 개발"…'금융권 AI 플랫폼' 내년 상반기 구축 2024-12-12 10:00:02
'한글 말뭉치' 제공…금융 분야 AI 가이드라인 개정도 (서울=연합뉴스) 임수정 기자 = 금융당국이 금융권 오픈소스 인공지능(AI) 활용을 통합 지원하는 '금융권 AI 플랫폼'을 내년 상반기까지 구축하기로 했다. 금융 전문성을 갖춘 AI 서비스 개발을 지원하기 위해 금융 분야 '한글 말뭉치(생성형 AI의...
- 뉴스 > 경제
- 바로가기
-
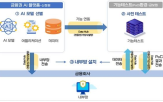
포티투마루에 국내 AI 모델 첫 인공지능 신뢰성 인증 2024-11-07 09:39:17
설명했다. 포티투마루의 LLM42는 한국어 말뭉치 데이터를 학습하고 자체 명령어 집합을 통해 미세 조정한 AI 언어 모델로 질의응답, 요약, 분류, 초안 작성 등 기능을 제공하는 기업대기업(B2B) 서비스용으로 개발됐다. 한국정보통신기술협회는 "LLM42 모델의 신뢰성 인증 과정에서 개인정보 보호권과 지식재산권 등 법규...
- 뉴스 > 경제
- 바로가기

-
현대엔지니어링, 플랜트·건설 특화 LLM 개발·시연 2024-10-21 10:49:26
현대엔지니어링은 젠티와 협력해 165억개의 말뭉치 토큰으로 이뤄진 방대한 플랜트 건설 분야 데이터를 학습한 파운데이션 모델을 개발했으며, 전문 엔지니어링 자료와 정제된 사내 데이터를 학습시켜 잘못된 정보를 사실인 것처럼 제시하는 '환각 현상'을 줄이고 답변의 신뢰도를 높였다. 최종 성능 검사 결과,...
- 뉴스 > 경제
- 바로가기

-
연매출 50억 '비건 베이커리' 브랜드 매물로 2024-08-22 11:15:24
플랫폼 매출뿐만 아니라 다년간 확보한 말뭉치, 번역 데이터를 활용해 부가가치 창출이 가능하다. 특히 다양한 산업과의 협업 경험은 향후 사업 확장에 중요한 자산이 될 것"이라고 평가했다. 알루미늄과 알루미늄 합금 소재의 표면처리를 전문으로 하는 연매출 50억원의 C사도 매각 중이다. 업력 30년차로 건축·전자제품...
- 뉴스 > 경제
- 바로가기

-
[커버스토리] '대륙의 실수'는 옛말…차이나 테크의 역습 2024-07-22 10:01:01
데 쓰이는 토큰(말뭉치)은 AI 칩의 성능을 보완해줄 수 있어 매우 중요합니다. 그런데 네이버가 2021년 선보인 한국 최초 LLM에 5600억 개의 토큰을 투입할 때 중국 텐센트는 자체 LLM 모델인 훈위안에 최근까지 3조 개 넘게 토큰을 투입했습니다. 투자 규모도 마치 인해전술을 펴는 것 같습니다. 반도체는 첨단 초미세...
- 뉴스 >
- 바로가기

-
"美中 AI 역량, 韓日 등 '2위 그룹'과 격차↑…中 논문 美 추월" 2024-07-07 12:24:27
보고서는 세계 2위로 올라선 중국의 경우 "여전히 부족한 점이 일부 존재하고, 특히 데이터 개발·이용과 원천 혁신 등 방면에서 강화가 필요하다"며 데이터 자원 확충과 공공 데이터 개방 메커니즘 완비로 대형 말뭉치를 만들고, 고급 인력 유치·육성을 확대해야 한다고 제언했다. xing@yna.co.kr (끝) <저작권자(c)...
- 뉴스 > 정치·사회
- 바로가기

-
'토큰 3조개' 익힌 텐센트 훈위안, 챗GPT보다 학습속도 빨라 2024-04-21 19:15:33
토큰(말뭉치) 수다. 지난해 9월 첫 공개 때 밝힌 토큰 규모가 2조 개인 만큼 7개월 동안 50%나 늘린 셈이다. 네이버가 2021년 선보인 한국 최초 LLM이 5600억 토큰을 학습한 것을 감안하면 파격적인 수준이다. ‘챗GPT의 아버지’로 불리는 샘 올트먼의 오픈AI도 2020년 3000억 개의 토큰을 투입해 GPT3를 출범시켰고, 최근...
- 뉴스 > 산업
- 바로가기






